CBM20
<- Back to dbCAN-subUnique features of dbCAN-sub: dbCAN-sub is developed as the first comprehensive CAZyme subfamily HMM database (including CBMs) to enable substrate annotation for CAZymes. The subfamily HMMdb (Figure 1) is derived from 25,487 CAZyme subfamilies classified by eCAMI (enzyme Classification And Motif Identification), a new k-mer based tool that we published in 2020 for the classification of enzyme families into subfamilies using a bipartite network algorithm (1). eCAMI was integrated into our popular dbCAN2 meta server in 2021 to replace Hotpep (2) according to a recent CAZyme annotation tool evaluation work from an independent group (3). Like CUPP, eCAMI can assign proteins to subfamilies with EC numbers (colored curves in Figure 1). However, both CUPP and eCAMI suffer from high demands of computer CPU and memory. eCAMI can annotate not only the catalytic enzyme domains but also the carbohydrate binding CBM domains. A very recent paper found that eCAMI tends to produce more granular subfamilies (4) than CUPP, and thus produces a higher percentage of subfamilies with a single EC number, allowing more specific substrate inference.
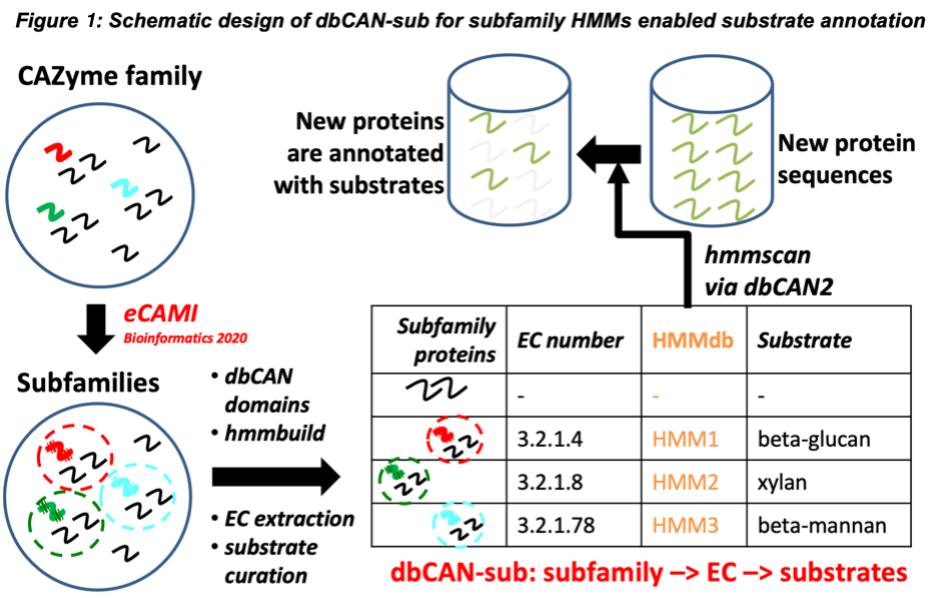
dbCAN-sub uses HMMs instead of k-mer peptides for subfamily assignment. Using HMMs has advantages: (i) significantly lower computer memory use; (ii) parallel computing to reduce CPU time; (iii) statistical significance E-value and domain positions reported by HMMER search. In other words, to address the computing cost issue, we have converted each eCAMI subfamily into an HMM, which was built from dbCAN domain sequence alignment of the subfamily.
More importantly, dbCAN-sub enables carbohydrate substrate annotation with a manually curated mapping table between CAZyme subfamily, characterized CAZymes, EC numbers, and glycan substrates. We constructed this mapping table by curating the CAZy family webpages for experimentally characterized proteins (e.g., GH5). Most of these webpages contain external links from EC numbers to the Enzyme database and from characterized protein IDs to the PubMed pages of biochemical reference papers. In most cases, we could obtain the substrate information for subfamilies by skimming through the paper abstracts or EC descriptions using EC numbers of experimentally characterized proteins in the subfamilies. For all CBM families and some enzyme families, we were able to extract the substrate information from the CAZy webpages without EC.
We have built a webpage for each CAZyme subfamily to provide all the necessary information that users need to understand what data the subfamily HMM was built upon: (i) a summary table with various counts of CAZy proteins including the download links to the fasta sequences; (ii) a substrate table with EC numbers and curated substrates from CAZy webpages and literature; (iii) a member protein table with all CAZy protein IDs and their subfamily assignments in the CAZy and CUPP databases (if exist). All these tables, dbCAN-sub HMMs, sequence alignments, and fasta sequences can be downloaded from the dbCAN-sub website.
Lastly, the dbCAN-sub subfamily HMMdb is integrated into our popular dbCAN2 meta server and the standalone run_dbcan program to allow the glycan substrate annotation for user submitted (meta)genomes.
Future update: We plan to update dbCAN-sub annually as new sequences and families are added in the CAZy database. New subfamilies will be created if the new CAZy sequences have higher similarity to eCAMI previously unclassified sequences or to each other than to existing subfamilies. The dbCAN-sub database will be a new addition to our popular dbCAN family tool suite (dbCAN2, dbCAN-seq, dbCAN-PUL, eCAMI), which focuses on CAZyme bioinformatics and carbohydrate metabolism.